Toward large-scale vulnerability discovery using Machine learning(Published 2016 in CODASPY
DOI:10.1145/2857705.2857720)
What is the problem?
It can predict large-scale vulnerability of binary programswhich mainly contain memory corruptions by using Machine Learning techniques and help human to discover the vulnerability.
Why is the problem important?
OS contain a large number of binary executable. Current methodologies and tools for an OS scale program testing within limited time budget are still missing. More importantly, only a few tools can operate on the binary code. one of the most effective vulnerability detection techniques (dynamic) still depends on large fuzzing campaigns, providing the target program with various inputs in order to produce crashes (such as core dump) that need to be (manually) analyzed afterwards. This is a time-consuming work.Therefore, there is a strong need for techniques to be used as fast predictors, to quickly identify which programs are more likely to contain a vulnerability, in order to direct the fuzzing process. we present a machine learning technique that uses lightweight static and dynamic features to predict if a test case is likely to contain a software vulnerability (limited to memory corruptions).
classifier 1: vulnerability or not?
classifier 2: which type?
What is the method
The method is to use Machine Learning to solve memory corruptions. The process contain dataset VDiscovery ,featrue extraction, data processing and model
- Dataset:
VDiscoveryis structured by analyzing 1039 test case taken corresponding to every different executable program which are distributed over 496 packages from Debian Bug Tracker. - featrue extraction: it is respectively
static featrueanddynamic featrue.static featrue :a set of finite sequence calls to the standard C library.- Disassemble a binary program into an assembly instruction. When traversing the program, all the calls to the standard C library are extracted according to the execution order of the instructions. If a conditional jump is encountered, a path is randomly selected. End of a sequence is encountered when a return statement or an indirect jump is encountered.
dynamic featrue:Such features are extracted by executing for a limited time a test case and hooking program
events, collecting them in a sequence. We define program events as either a call to the C standard library function (abstracted simply as fc i ) with its arguments or the finalstate of the process.(fc i (arg 1 ,..,arg n ) | FinalState(Exit | Crash | Abort | Timeout)) and its arguments are replaced with a suitable subtype we define.(e.g.Ptr32/ HPtr32/ SPtr32)
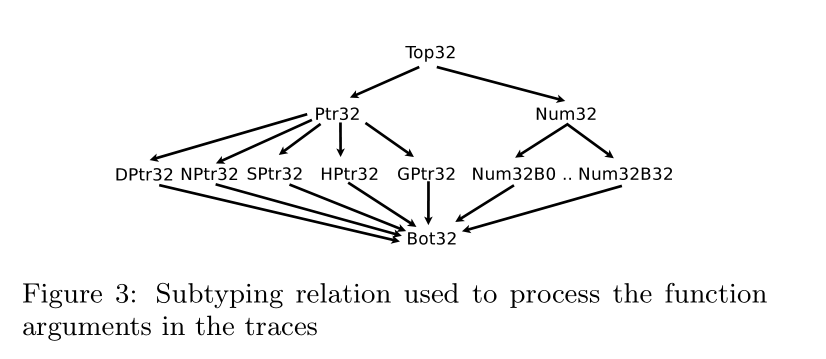
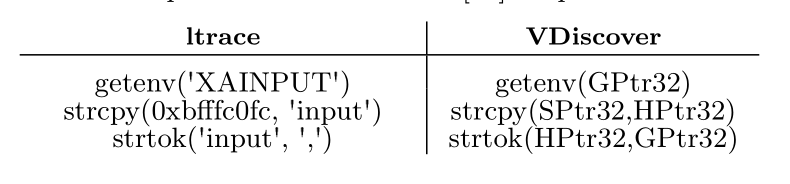
models :
logistic regression/a multilayer perceptron (MLP)/Random Forest.- Contrast between
static and dynamic features;Comparison betweenmodels; Compare this work witha simple fuzze.
Error Evaluation: To obtain a single error percentage, we can
average false positives and false negatives into a balanced test error- experiment result :

Thinking
- 具体的特征列表?
- 缺乏一个具体的讲解例子
- 单纯的算法比较其实并没有多大的意思
- 不理解Error Evaluation,感觉比较怪