VulDeePecker: A Deep Learning-Based System for Vulnerability Detection
中文标题:
VulDeePecker:一个基于深度学习的漏洞检测系统
简介:
vulDeePecer是基于深度学习的智能漏洞检测系统,可以
降低软件漏洞的漏报率(1)以及解决专家手动自定义繁杂的软件漏洞特征的工作(2)。vulDeePecer与目前存在静态漏洞检测软件工具进行实验对比(例如Flawfinder、RATS、Checkmarx、RATS、VUDDY,VulPecker),vulDeePecer针对相应类型的软件漏洞,它模型正确识别率达到了78%以上,相比其他工具,它检测漏洞是更有成效。
中文摘要:
自动检测软件漏洞是一个重要的研究课题。但是,目前解决方案主要是依赖人类专家去自定义特征并且经常错过了许多软件漏洞(例如软件出现高漏报率
(FNR))。在这篇论文中,作者提出了基于深度学习的软件漏洞检测去减轻人工手动自动义繁杂软件漏洞的特征的工作任务,同时,作者也提到适用于深度学习的软件程序的表示形式(即如何表达软件程序),这个表示形式是代码小工具code gadget(主要保持上下文关系代码行(不需要连续性)即可),再将code gadget转为矢量vetcor。从而设计出基于深度学习软件漏洞系统vulDeePecer,作者为了评估vulDeePecer,提出了第一个深度学习方法的漏洞数据集。实验过程中,vulDeePecer检测漏洞更有成效,作者用它来检测现有3个软件产品(Xen, Seamonkey, and Libav)并且发现了4个漏洞(这些漏洞并没有被报告在国家安全漏洞数据库NVD,以及供应商通过发布产品新版本默默修补了这些漏洞),而其他软件漏洞检测工具几乎遗漏了这几个漏洞。
技术路线:
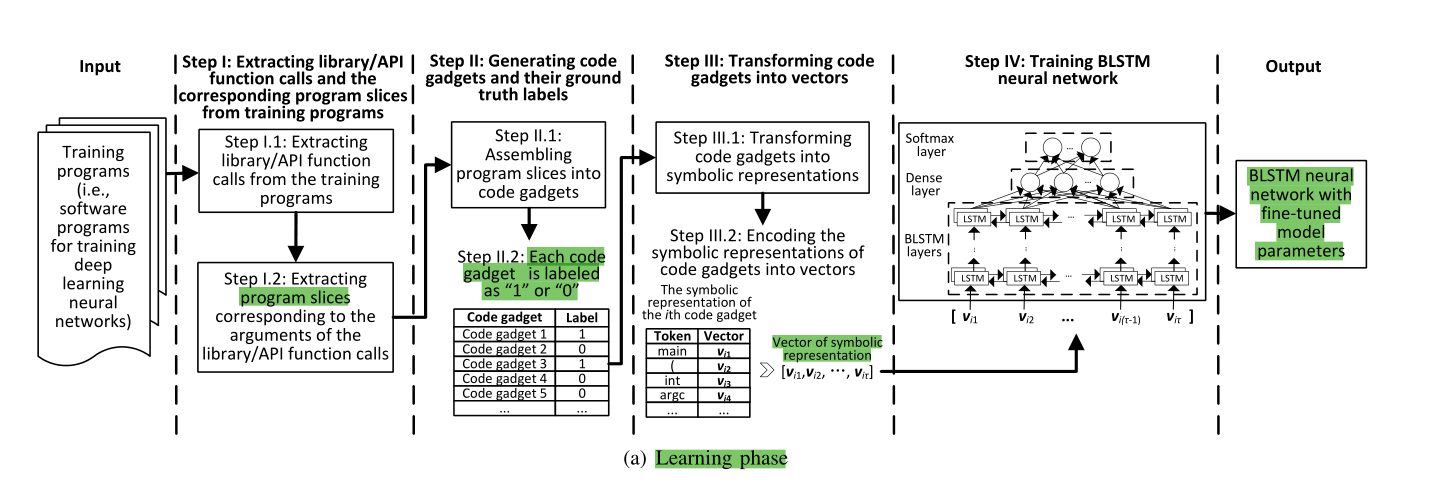
Learning Phase:
1 .
Extracting the library/API function calls and the corresponding program slices.
(1.1)从训练程序集中提取library/API function calls(目前的VulDeePecker主要集中在CWE-119与CWE-399相关的library/API function calls)
(1.2) 在从1.1中提取的library/API function calls的每个参数中提取相关代码片段(数据流处理)
Generating code gadgets of the training programs and their ground truth labels
(2.1)组装1.2中提取到的代码片段为代码小工具(中间程序表示方式code gadgets.每个library/API function calls就有一个code gadgets)
(2.2)将组装好的code gadgets打上标签(用1表示漏洞,0表示正常程序,作者已知的程序类型)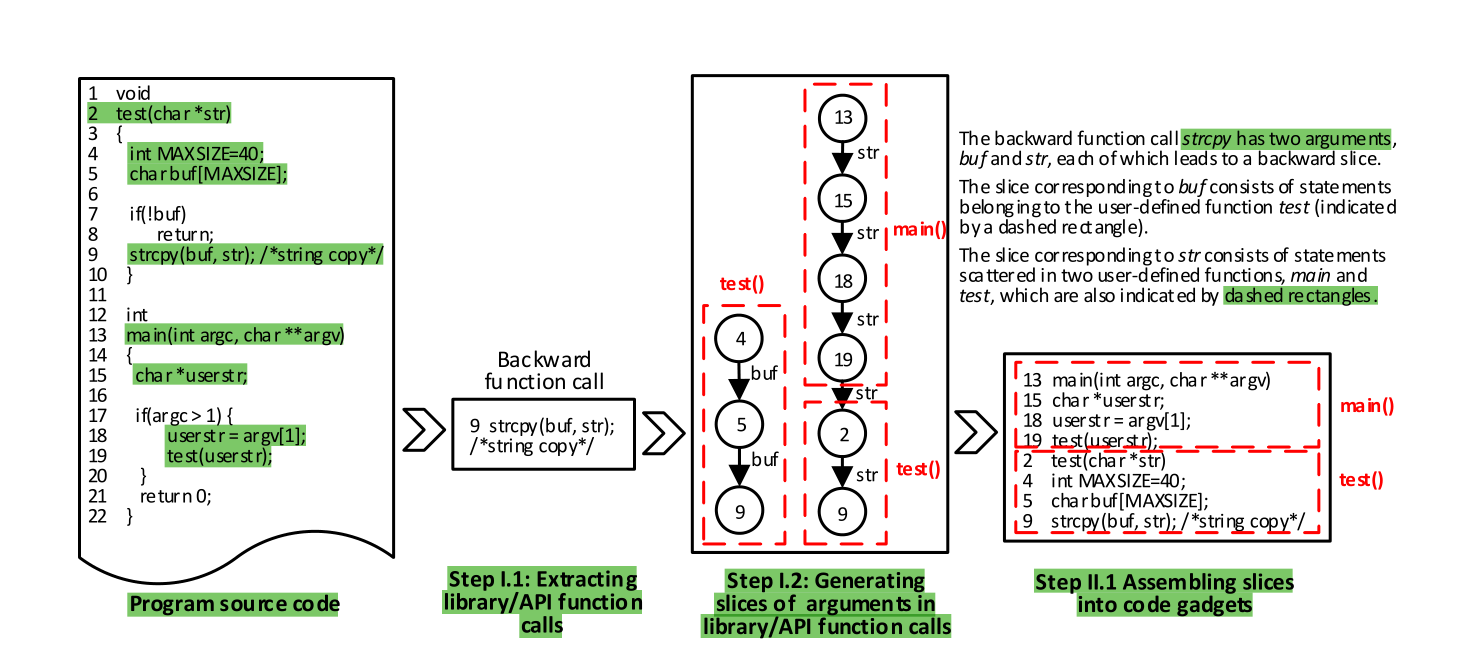
3 .
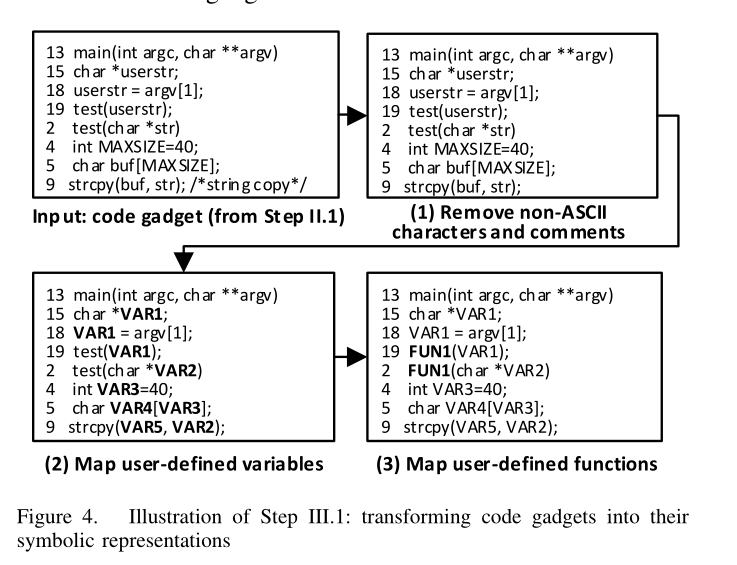
Transforming code gadgets into vector representations
(3.1)将code gadgets转换为精确的符号表示(symbolic represetations,为了保留程序某些语义信息)
(3.2)将(3.1)获取到的symbolic represetations编码为向量(vectors,作为BLSTM神经网络的输入源)
Traning a BLSTM neural network( 输出->生成漏洞匹配的模型)
Detection Phase(Given one or multiple target programs, we extract library/API function calls from them as well as the corresponding program slices, which are assembled into code gadgets. The code gadgets are transformed into
their symbolic representations, which are encoded into vectors and used as input to the trained BLSTM neural network.
The network outputs which vectors, and therefore which code gadgets, are vulnerable (“1”) or not (“0”). If a code gadget is
vulnerable, it pins down the location of the vulnerability in thetarget program):
Transforming target programs into code gadgets and vectors.Detection7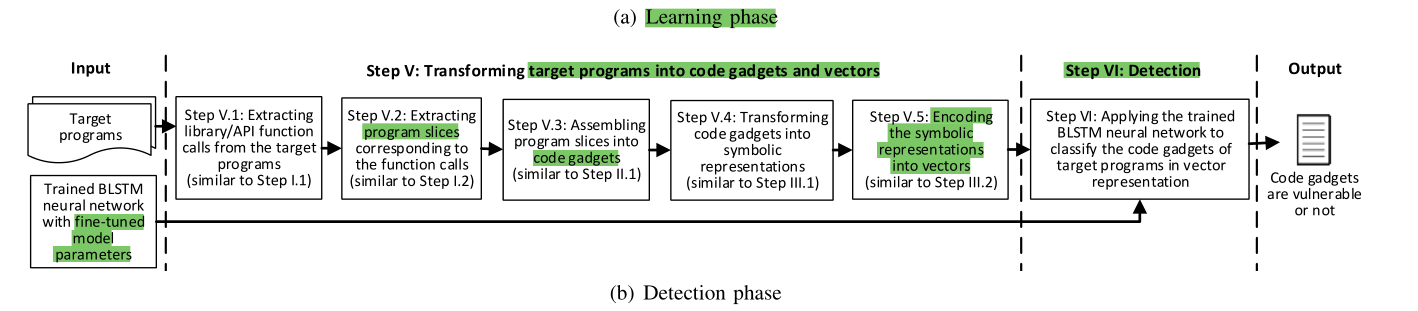
技术路线总结:训练阶段 主要是通过源代码->代码小工具(中间程序表示)->向量,经过BLTSM神经网络训练生成漏洞匹配模式模型
检测阶段 用生成模型检测源码是否是有漏洞,并且确定其位置。
贡献:
- 第一个提出基于深度学习的漏洞检测的研究
- 作者设计跟实施一个基于深度学习的漏洞检测系统,简称Vulnerability Deep Pecker(
vulDeePecer)- 作者用于评估
vulDeePecer以及未来其他基于深度学习的漏洞检测系统的数据集,并已共享于https://github.com/CGCL-codes/VulDeePecker
局限性
VulDeePecker目前的设计仅限于通过假定程序源码是可用的来解决漏洞检测VulDeePecker目前只能处理C/C++程序VulDeePecker目前的设计只能处理 与漏洞相关连的类库/API方法VulDeePecker目前的设计只适用数据流分析,不包含控制流分析VulDeePecker目前的设计仅限于BLSTM神经网络VulDeePecker目前的设计仅限于内存溢出漏洞与资源管理漏洞
vulnerability detection approach
current vulnerabilty detection approach mainly is
code similary-basedandpattern-based.
- The pattern-based detection approach typically requires multiple instances of the same or similar vulnerability before a pattern can be identified.
The code-similarity based detection approach only requires a single instance of vulnerability.
pattern-based: this approach can be devided three categories- First categories: the patterns are generated manually by human experts(e.g. ,open source tools
Flawfinder/RATS/ITS4and Commerical toolsCheckmarx/Fortify/Coverity) - Second categories: the patterns are generated semi-automicially form pre-classified vulnerabilities(e.g.,
missing check vulnerabilities/taint-style vulnerabilities/information leakage vulnerabilities/a pattern is specific to a type of vulnerabilities) - third categories: patterns are generated semi-automatically from type-agnostic vulnerabilities (i.e., no need to pre-classify them into different types). These methods
use machine learning techniques, which rely on human experts for defining features to characterize vulnerabilities
- First categories: the patterns are generated manually by human experts(e.g. ,open source tools
Code similarity-based approach:This approach has three steps- First step: divide a program into some
code fragments - Second step : represent each code fragment in the
abstract fashion, includingtokens,trees, andgraphs - third step: compute the similarity between code fragments via their abstract representations obtained in the second step.
- First step: divide a program into some